
引擎和播放器
SG Com 有两个主要组件:引擎和播放器。
引擎执行主要的处理工作:将输入的音频流转换为同步脸部动画。输出动画包括嘴型同步、全脸表情、眨眼、眼球微动,甚至头部动作,所有这些都由说话者的声音通过 Speech Graphics 算法驱动。音频输入和动画输出之间的处理延迟很小(50 毫秒)。一个引擎只有一个音频源,只能为一个角色生成动画。有关输入音频,请参阅 SG Com 输入。
引擎输出必须流式传输到播放器才能缓冲、解码和播放。推进播放器中的时间,并根据获得的动画值对场景进行更新,即可自动生成角色的面部动画。动画值会根据请求的时间自动插值。
网络使用的情况与本地使用的情况
输入语音可用于在本地或通过网络远程驱动动画角色。在本地使用的情况下,引擎和播放器都在同一台机器上:

在远程使用的情况下,可以在本地通过引擎运行音频,然后将引擎输出(和音频)发送到远程播放器进行缓冲和输出。下面描述了通过网络进行双向对话,其中每一方都有一个用于处理输入音频的本地引擎和一个用于输出对方动画的播放器。
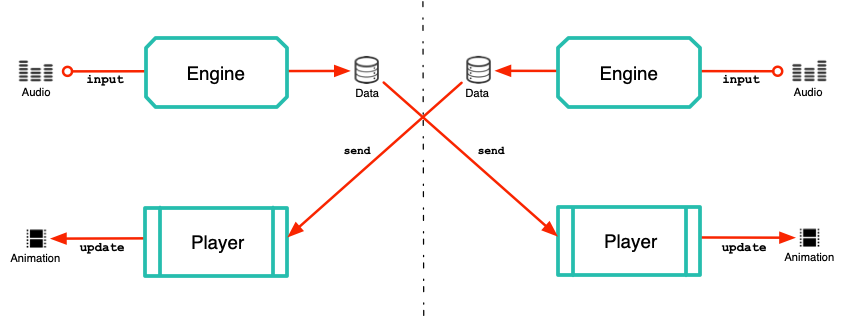
SG Com 不会执行网络操作。数据必须由应用程序传输。要在完全联网的端到端服务中享受 SG Com 的服务,请参阅 Rapport.cloud。
引擎闲置
SG Com 不需要声音就能继续对目标角色生成动作。即使音频输入中断,引擎也可以继续接管,并生成非嘴部动作来响应情绪控制器。这被称为闲置。请注意,闲置会添加没有相应音频输入的输出,在同步音频和动画输出时必须考虑到这一点。
生成闲置动作的方法有两种:在没有音频输入的情况下运行引擎,或为音频输入空白。请参阅 SG Com API 教程中的闲置模式。
同步输出
为了使音频和动画输出同步,必须牢记以下几点:
SG Com 延迟。音频样本输入引擎后,会有 50 毫秒的延迟,然后才会生成相应的动画输出包。这意味着会产生可感知的不同步。因此,从麦克风或其他来源接收的音频不能在输入到引擎的同时立即输出。它必须与动画同步后再输出。
时间基于音频。动画播放循环包括向播放器传递时间值,以获取动画帧。播放器的时域基于进入引擎的音频(加上任何闲置的时间)。因此,要保持动画与音频同步,就必须知道音频的时间戳,并更正任何丢失的音频数据。时间 0 对应输入引擎的音频的第一帧。
元数据更新
除了生成实时动画外,SG Com 引擎还会通过其内部算法生成更新,这些更新可用于向外部其他进程提供信息。目前,SG Com 会为以下类型的更改生成更新:
检测到的自动模式更改(积极、消极、笑声、用力声等)
情绪模式更改
脸部表情更改
语音检测更改(语音或无语音)
呼吸方向更改(吸气或呼气)
在每种情况下,通知都附有描述新状态(如新情绪模式)的文本有效载荷。