
This section explains the proprietary SGX time series data types visible in the event editor in SGX Director, and the file formats to which they may be saved. SGX has three time series types:
-
Regular Time Series
-
Irregular Time Series
-
Categorical Time Series
These are described in detail below.
Regular Time Series
A Regular Time Series (RTS) contains multi-channel data at a regular sample rate. For example, below is an RTS containing animation data. Each line represents an animation channel, and the sample rate is the frame rate of the animation.
File format (.rts)
The file has three parts:
-
The first row contains a single value which is the sample rate.
-
The second row is a comma-separated sequence of channel labels.
-
Each subsequent row is a sample of the channel values at the given sample rate.
30
head.tx,head.ty,head.tz,head.rx,head.ry,head.rz,head.sx,head.sy,...
1.999987416,3.86E-06,-1.80E-06,-0.000571836,-0.002572273,-0.0001...
1.999848472,9.27E-05,-1.87E-05,-0.005927532,-0.026663633,-0.0065...
1.999549227,0.000318193,-5.29E-05,-0.016749984,-0.075345895,-0.0...
1.999104374,0.000668944,-0.000102617,-0.032516878,-0.146269352,-...
1.998546331,0.001117568,-0.00016447,-0.052116501,-0.234432717,-0...
1.997909577,0.001634493,-0.000234717,-0.074376584,-0.334562011,-...
1.997233413,0.002185685,-0.000309162,-0.097967676,-0.440676092,-...
...
Irregular Time Series
An Irregular Time Series (ITS) contains irregularly sampled multi-channel data, with an interpolation function. For example, below is an example of prosody, which is an ITS with three channels: syllable stress, phrase stress and phrase speed.
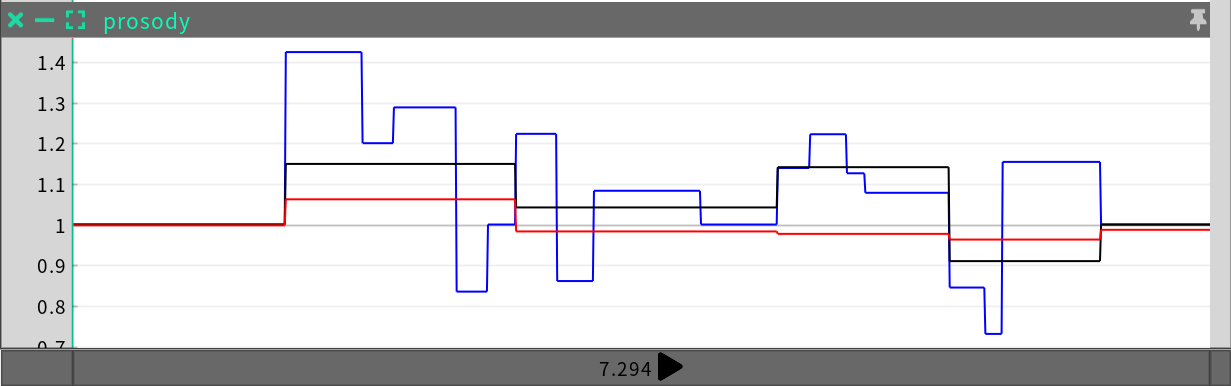
File format (.its)
The file has a heading for each channel followed by the irregularly timed samples of that channel.
"syllable_stress" >constant
1370.000,1.000,0.000
1857.000,1.424,0.000
2057.000,1.200,0.000
2462.000,1.288,0.000
2660.000,0.835,0.000
2840.000,1.000,0.000
3107.000,1.223,0.000
3340.000,0.861,0.000
4030.000,1.083,0.000
4520.000,1.000,0.000
4730.000,1.139,0.000
4967.000,1.222,0.000
5080.000,1.126,0.000
5622.000,1.078,0.000
5850.000,0.845,0.000
5962.000,0.731,0.000
6590.000,1.154,0.000
7294.125,1.000,0.000
"phrase_stress" >constant
1370.000,1.000,0.000
2840.000,1.149,0.000
4520.000,1.042,0.000
5622.000,1.141,0.000
6590.000,0.910,0.000
7294.125,1.000,0.000
"phrase_speed" >constant
1370.000,0.998,0.000
2840.000,1.062,0.000
4520.000,0.983,0.000
5622.000,0.977,0.000
6590.000,0.963,0.000
7294.125,0.987,0.000
For each channel section, the first row consists of a channel header in the format:
"channel-name" >interpolation-function
For example:
"syllable_stress" >constant
Each row after the header is a time,value data point in the channel. Each such row has the format
time(ms),value,confidence
where time(ms) is the time of the data point in milliseconds and value is the value of the channel at that data point. Confidence is generally not used and is set to 0.0. For example:
1857.000,1.424,0.000
denotes a data point at time 1857 ms, with value 1.424.
Interpolation function
For present purposes, all SGX ITS files use constant interpolation. This means that the value of the channel is constant in between time points. Specifically, the channel value at any time is that of the next upcoming data point. For example,

With constant interpolation, the value of data point A sets the value for the interval ending at A, and the data point B sets the value for the interval ending at B.
Categorical Time Series
A Categorical Time Series contains a set of labeled intervals and possibly subintervals. For example, below is an example of phone alignment, which is a CTS with two tiers: words and phones.

File format (.seg)
The file format for a Categorical Time Series (note it has the suffix .seg for "segmentation” rather than .cts) contains a list of interval boundaries:
1370.0 0.000 [^] [^]
1550.0 0.000 [t]
1680.0 0.000 [aa]
1820.0 0.000 [ih]
1920.0 0.000 [g]
1980.0 0.000 [ax] [tyger]
2160.0 0.000 [t]
2290.0 0.000 [aa]
2390.0 0.000 [ih]
2520.0 0.000 [g]
2660.0 0.000 [ax] [tyger]
2840.0 0.000 [^] [^]
2920.0 0.000 [b]
3100.0 0.000 [ehx]
3160.0 0.000 [n]
3210.0 0.000 [ih]
3340.0 0.000 [ng] [burning]
3430.0 0.000 [b]
3480.0 0.000 [rh]
3610.0 0.000 [aa]
3740.0 0.000 [ih]
4030.0 0.000 [t] [bright]
4520.0 0.000 [^] [^]
4630.0 0.000 [ih]
4720.0 0.000 [n] [in]
4760.0 0.000 [dh]
4820.0 0.000 [ax] [the]
4980.0 0.000 [f]
5080.0 0.000 [oa]
5180.0 0.000 [rh]
5250.0 0.000 [ih]
5360.0 0.000 [s]
5470.0 0.000 [t]
5610.0 0.000 [s] [forests]
5740.0 0.000 [oa]
5850.0 0.000 [v] [of]
5900.0 0.000 [dh]
5960.0 0.000 [ax] [the]
6060.0 0.000 [n]
6180.0 0.000 [aa]
6310.0 0.000 [ih]
6590.0 0.000 [t] [night]
7460.0 0.000 [^] [^]
Each boundary definition contains:
-
a time value in milliseconds
-
a confidence value (usually set to 0.0)
-
a sequence of labels in square brackets
The number of labels on a boundary determine how many tiers that boundary spans. For example, the boundary
2660.0 0.000 [ax] [tyger]
has two labels, meaning it spans two tiers. This boundary is indicated by the red line below:

On each tier that the boundary spans, it marks a the end of a segment and gives that segment its corresponding label. The start of each segment is the preceding boundary on the same tier (or 0.0 if there is none). Thus on the first (phone) tier, the red boundary marks the end of a segment [ax],which starts at the preceding boundary on the first tier:

And on the second (word) tier, the red boundary marks the end of a segment[tyger], which starts at the preceding boundary on the second tier:
