
SGX offers users the ability to edit or export metadata. For these purposes it is useful to understand the metadata sequences found in events. These are described below.
For each sequence, the following information is provided:
-
a brief description of the metadata, including the time series type
-
the impact of editing it
-
its direct antecedents – i.e., the preceding sequences in the event that are used as input to its generation (see Reprocessing)
Primary metadata
This section covers the metadata sequences that are of primary interest for purposes of editing:
-
word alignment
-
phone alignment
-
lip sync
-
behavior mode
-
expressions
-
modifiers
Word alignment
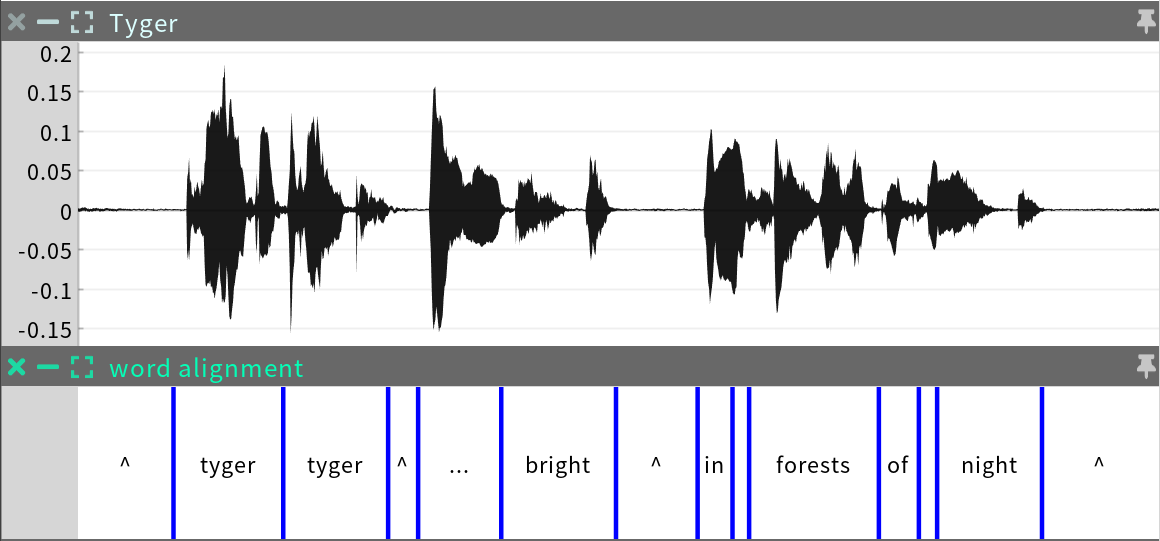
The word alignment is a Categorical Time Series consisting of an analysis of the timing of words in the audio. This sequence is only created in events that were processed with a transcript.
Editing: The word alignment boundaries may be shifted in cases where the pronunciation of words in the facial animation seems out of sync with the audio.
Antecedents: transcript
Phone alignment
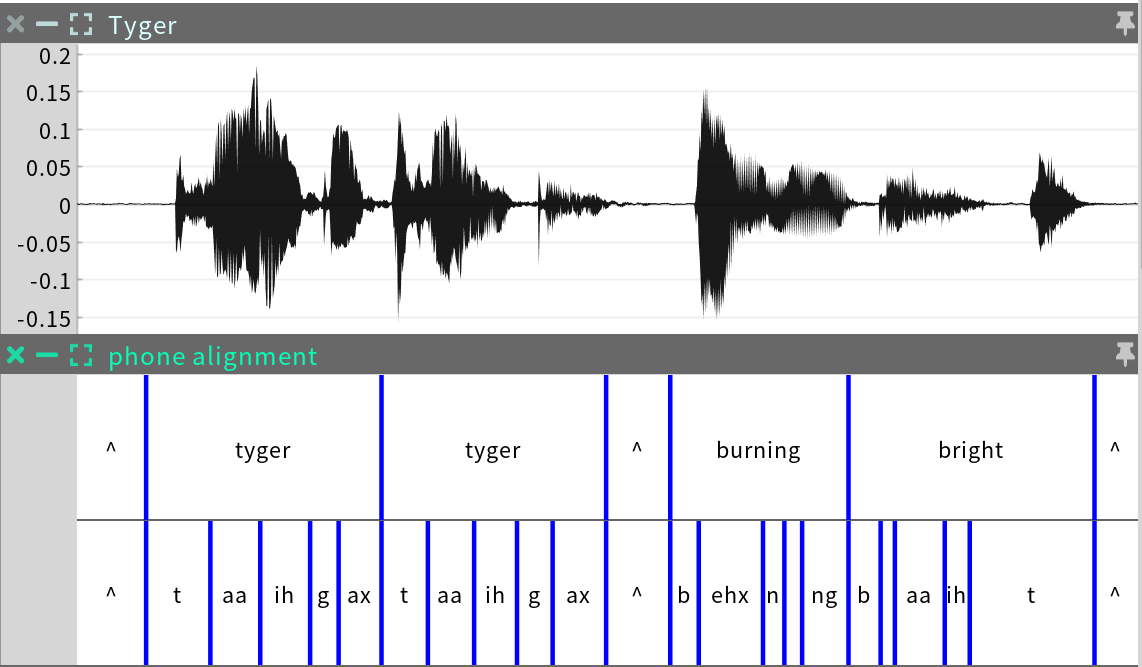
The phone alignment is a Categorical Time Series similar to the word alignment, but including subintervals for the phones (consonants and vowels) making up the words. Like word alignment, this sequence is only found in events that were processed with a transcript.
Editing: The phone alignment boundaries may be shifted in cases where the pronunciation of individual phones is out of sync with the audio. Because it has so many boundaries, editing the phone alignment is more laborious than editing the word alignment. And in most cases, editing the word alignment is sufficient as this will automatically realign the phones. So the phone alignment should only be edited if you really want to dig deeper into the phonetic timings.
Antecedents: word alignment
Lip sync
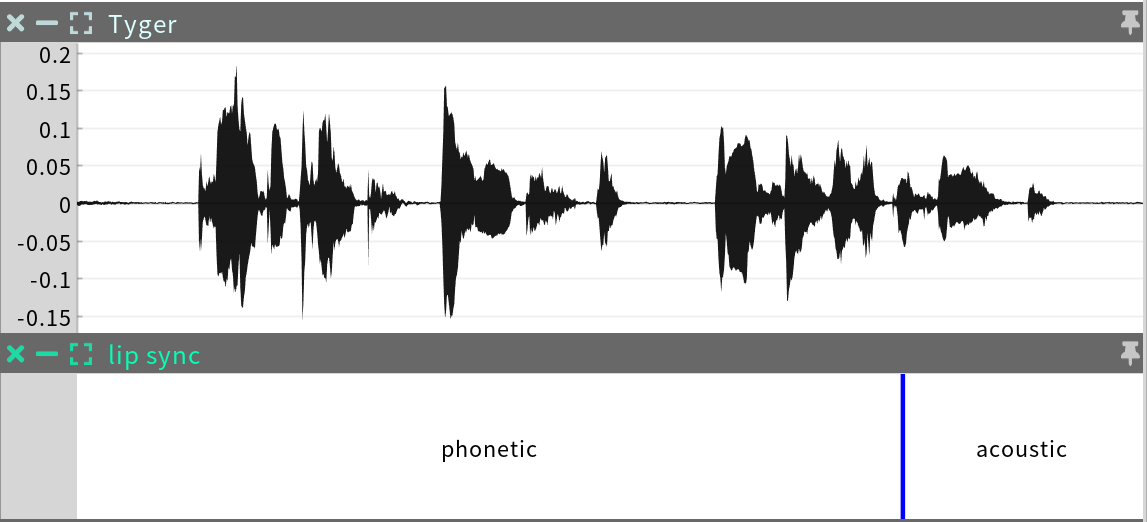
The lip sync sequence is a Categorical Time Series that indicates which lip sync system was used at any point in the animation – phonetic or acoustic. This sequence is only created in events that were processed with a transcript.
Editing: This may be used to edit the choice of lip sync system, if the user thinks another choice would work better over a particular interval.
Antecedents: phone alignment
Behavior mode
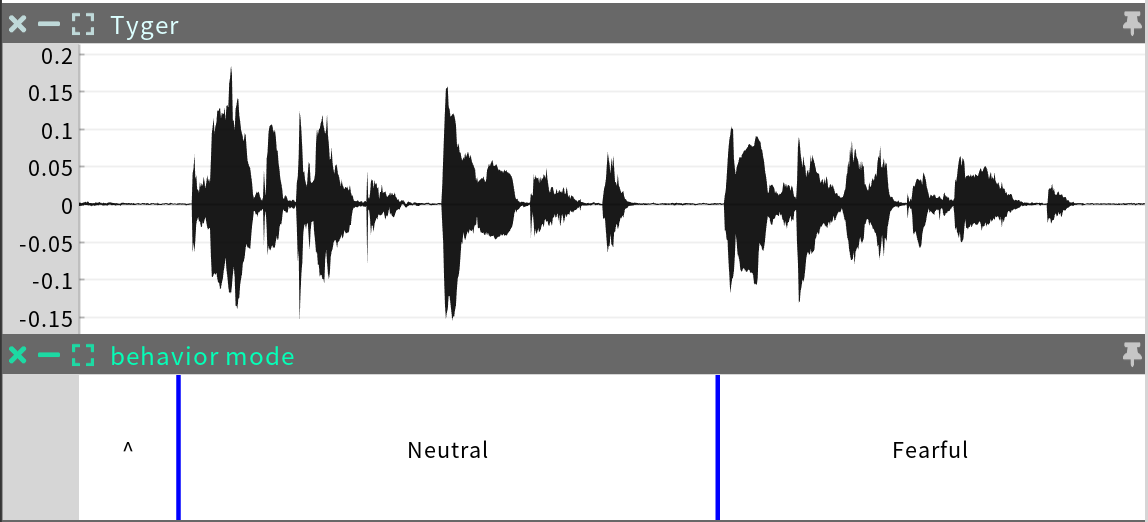
The behavior mode sequence is a Categorical Time Series that indicates which behavior mode of the character is active at any point in time.
Editing: This may be used to edit the choice and placement of behavior modes, leading to different nonverbal behaviors.
Antecedents: transcript, phrases
Expressions
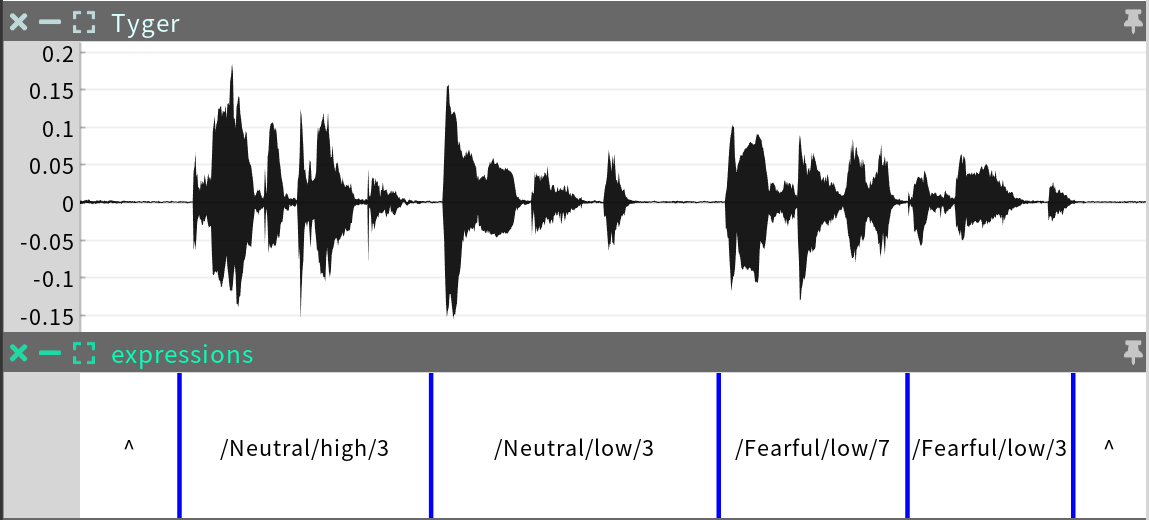
The expressions sequence is a Categorical Time Series that indicates which expression of the character is active at any point in time.
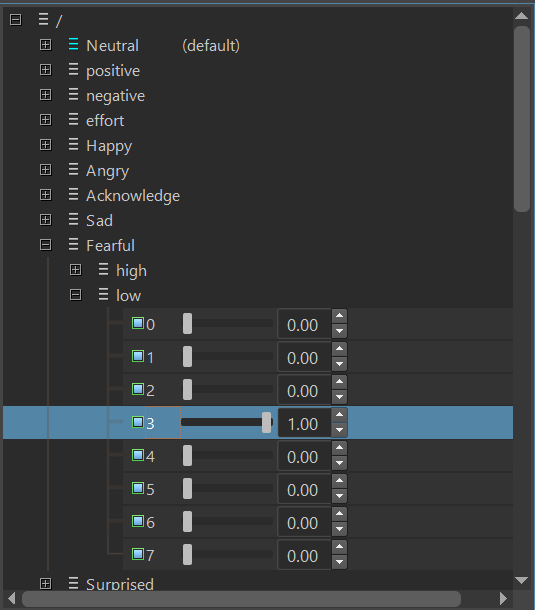
Expression labels are paths in the expression tree of the character. For example, “Fearful/low/3” in the sequence above refers to expression ”3” in the low-tone subset of the behavior mode “Fearful”, as shown below in SGX Studio.
Editing: This may be used to edit the choice and placement of expressions, leading to different nonverbal behaviors.
Antecedents: phrases, behavior mode
Modifiers
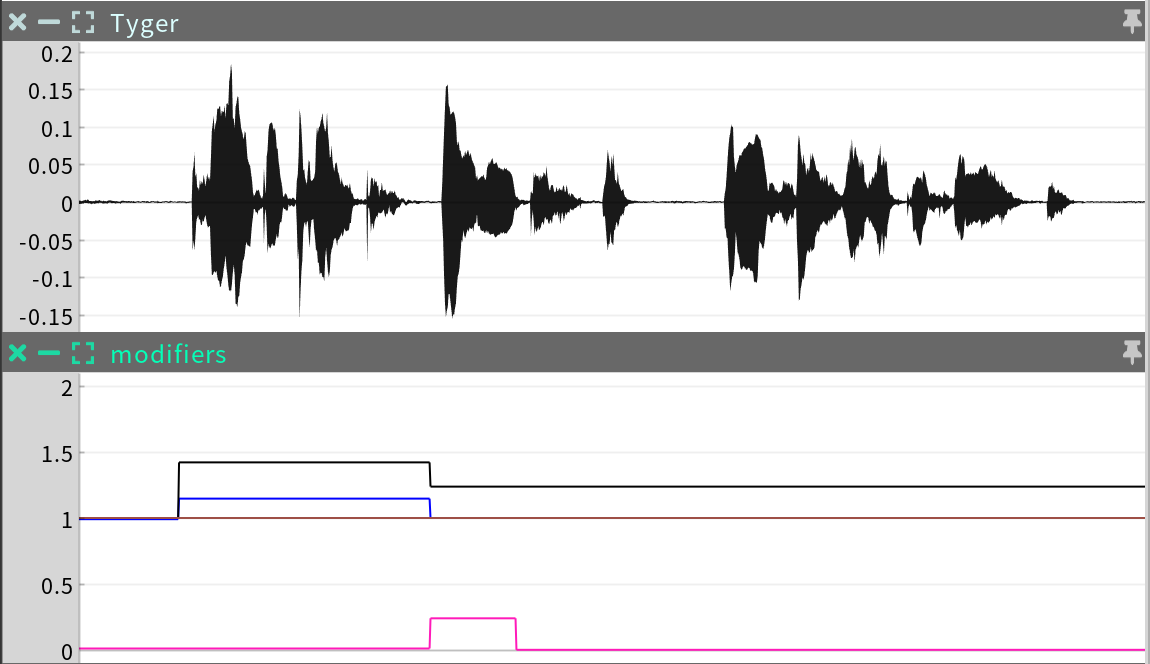
The modifiers sequence is an Irregular Time Series that plots the behavior modifiers over time.
Editing: This is used to edit the modifiers.
Antecedents: transcript
Prosodic metadata
This section covers prosodic metadata, which are analyses of intonation, stress and intensity in speech. These sequences are either not editable or are less likely to need editing, but could be useful for other purposes, particularly when exported. The prosodic metadata consists of the following four sequences:
-
intensity
-
pitch
-
prosody
-
phrases
Intensity
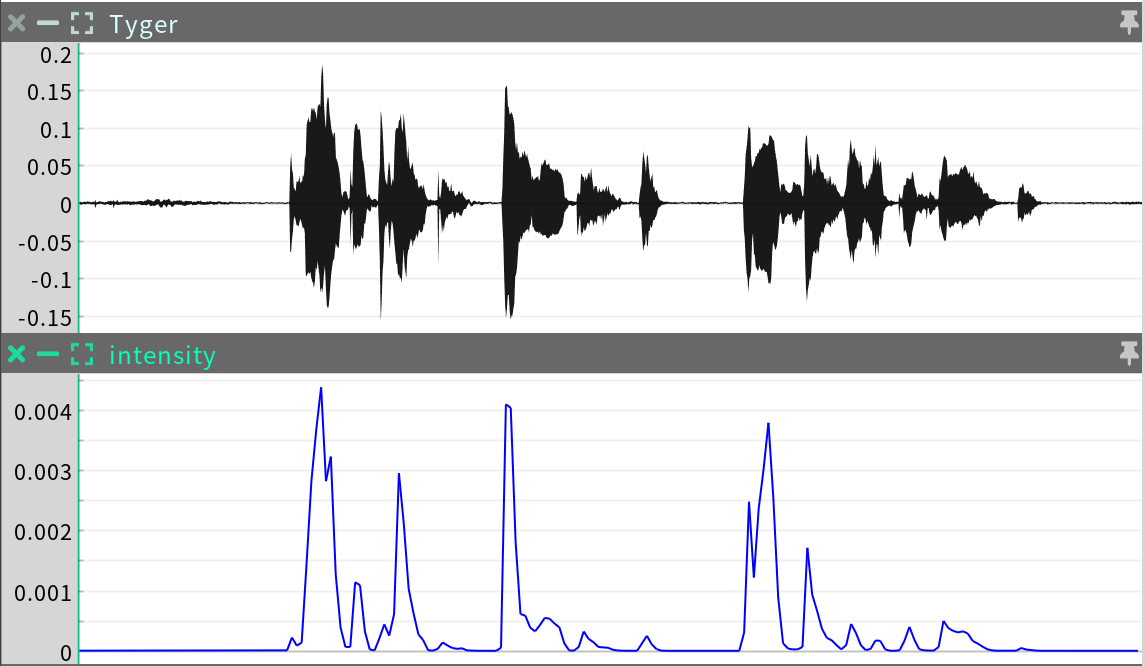
The intensity sequence is a Regular Time Series providing an analysis of acoustic intensity over time. This sequence is not editable.
Pitch
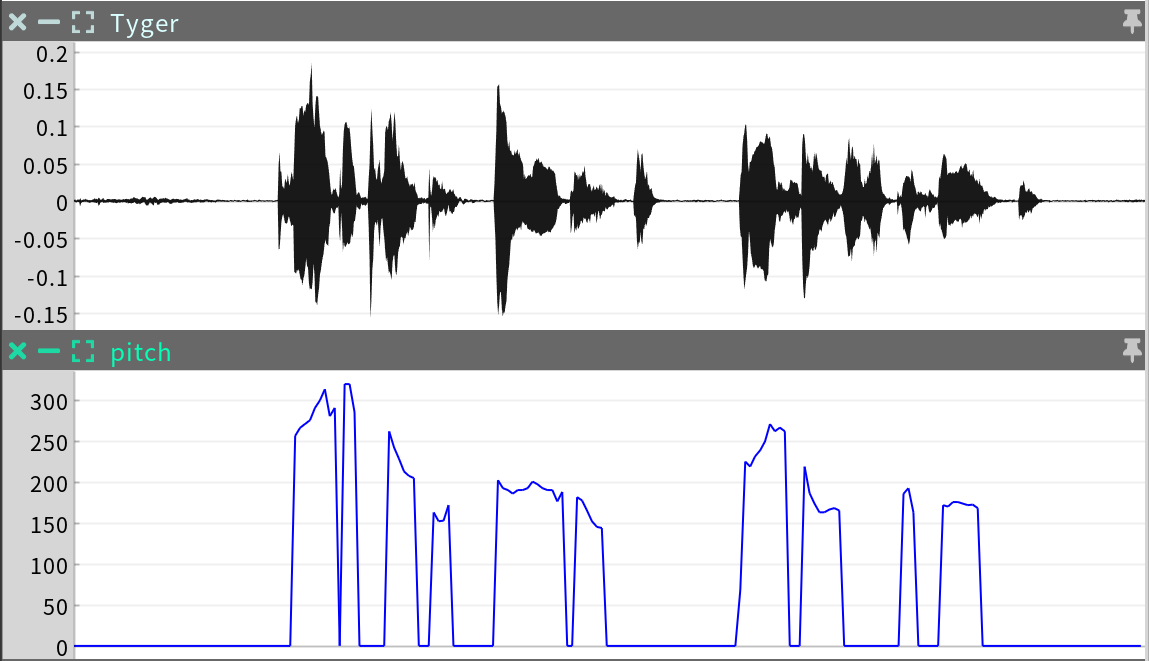
The pitch sequence is a Regular Time Series providing an analysis of pitch over time. The analysis defaults to 0.0 when no voicing is detected. This sequence is not editable.
Prosody
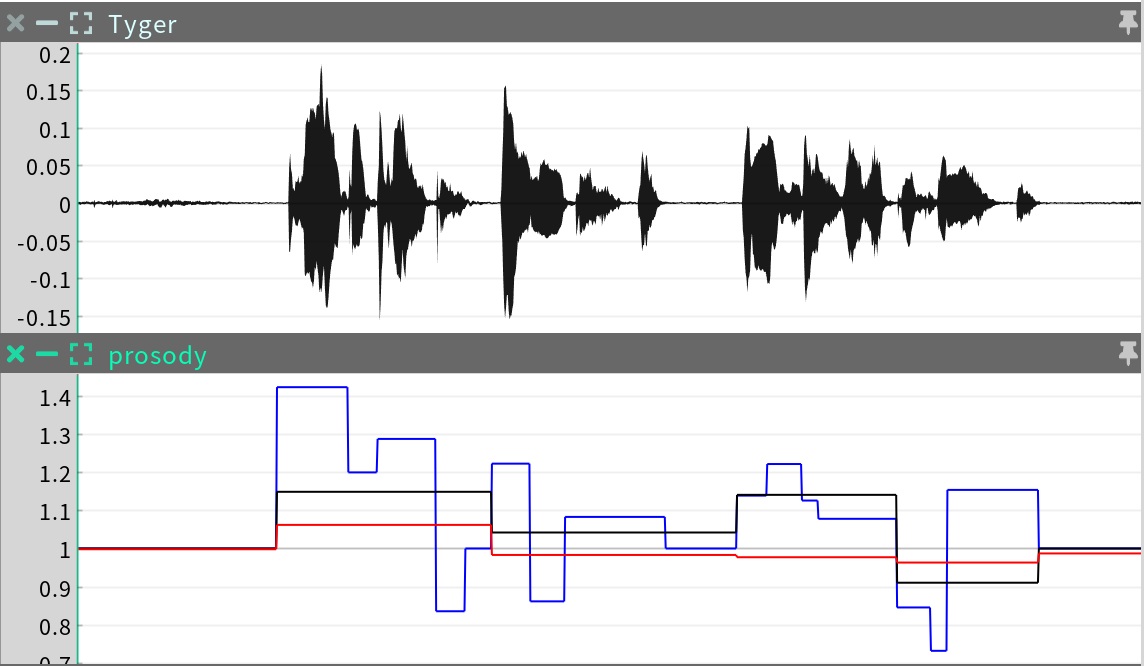
The prosody sequence is an Irregular Time Series plotting the analyzed stress patterns and speed of the speech over time. This analysis is used to determine the magnitude and speed of muscle movements during both speech and nonverbal behaviors.
There are three channels in the prosody sequence, each with a range of [0,2] around a “normal” value of 1.0.
-
syllable stress (blue): the degree of stress in each syllable (affects speech behavior)
-
phrase stress (black): the degree of stress in each phrase (affects nonverbal behavior)
-
phrase speed (red): the degree of speed in each phrase (affects speech and nonverbal behavior)
Editing: This sequence does not generally need to be edited, since it is usually easier – and just as effective – to edit the modifiers to alter the magnitude and speed of speech or nonverbal behavior.
Antecedents: transcript
Phrases
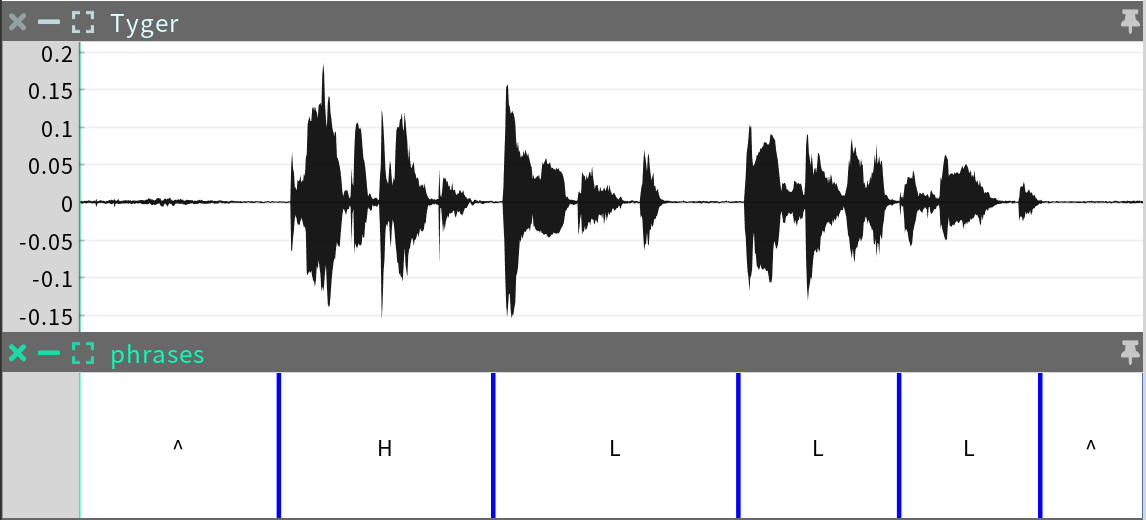
The phrases sequence is a Categorical Time Series that divides the timeline into intervals corresponding roughly to spoken phrases. Each phrase is categorized as high tone (H) or low tone (L) based on the intonation of the speech. The phrases form the intervals to which expressions are assigned, and their tones are used to select expressions when behavior modes are bi-tonal.
Editing: This sequence does not generally need to be edited, since the expressions that derive from it may be edited directly instead.
Antecedents: transcript