
本节介绍了在 SGX Director 的 event 编辑器中可以看到的 SGX 专有时间序列数据类型,以及可以保存这些数据的文件格式。SGX 有三种时间序列类型:
-
常规时间序列
-
不规则时间序列
-
分类时间序列
下面将详细介绍这些类型。
常规时间序列
常规时间序列 (RTS) 包含常规采样率的多通道数据。例如,下面是一个包含动画数据的 RTS。每一行代表一个动画通道,采样率为动画的帧率。
文件格式 (.rts)
该文件由三部分组成:
-
第一行包含一个值,即采样率。
-
第二行是以逗号分隔的通道标签序列。
-
随后的每一行都是在给定采样率下的通道值的采样。
30
head.tx,head.ty,head.tz,head.rx,head.ry,head.rz,head.sx,head.sy,...
1.999987416,3.86E-06,-1.80E-06,-0.000571836,-0.002572273,-0.0001...
1.999848472,9.27E-05,-1.87E-05,-0.005927532,-0.026663633,-0.0065...
1.999549227,0.000318193,-5.29E-05,-0.016749984,-0.075345895,-0.0...
1.999104374,0.000668944,-0.000102617,-0.032516878,-0.146269352,-...
1.998546331,0.001117568,-0.00016447,-0.052116501,-0.234432717,-0...
1.997909577,0.001634493,-0.000234717,-0.074376584,-0.334562011,-...
1.997233413,0.002185685,-0.000309162,-0.097967676,-0.440676092,-...
...
不规则时间序列
不规则时间序列 (ITS) 包含不规则采样的多通道数据,并带有插值函数。例如,下面是一个韵律的示例,它是一个包含三个通道的 ITS:音节重音、短语重音和短语速度。
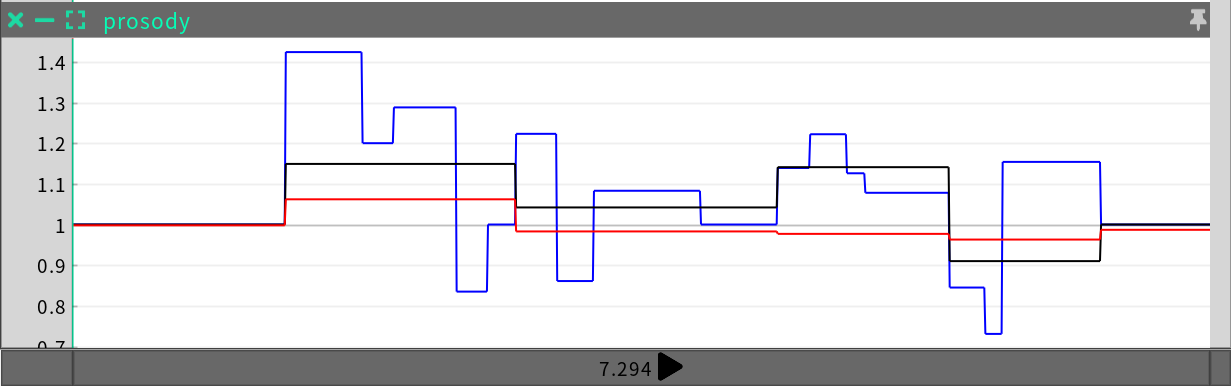
文件格式 (.its)
该文件中每个通道都有一个标头,后面是该通道的不规则定时采样。
"syllable_stress" >constant
1370.000,1.000,0.000
1857.000,1.424,0.000
2057.000,1.200,0.000
2462.000,1.288,0.000
2660.000,0.835,0.000
2840.000,1.000,0.000
3107.000,1.223,0.000
3340.000,0.861,0.000
4030.000,1.083,0.000
4520.000,1.000,0.000
4730.000,1.139,0.000
4967.000,1.222,0.000
5080.000,1.126,0.000
5622.000,1.078,0.000
5850.000,0.845,0.000
5962.000,0.731,0.000
6590.000,1.154,0.000
7294.125,1.000,0.000
"phrase_stress" >constant
1370.000,1.000,0.000
2840.000,1.149,0.000
4520.000,1.042,0.000
5622.000,1.141,0.000
6590.000,0.910,0.000
7294.125,1.000,0.000
"phrase_speed" >constant
1370.000,0.998,0.000
2840.000,1.062,0.000
4520.000,0.983,0.000
5622.000,0.977,0.000
6590.000,0.963,0.000
7294.125,0.987,0.000
每个通道部分的第一行都有一个通道标头,格式如下:
“通道名称” >插值函数
示例:
"syllable_stress" >constant
标头之后的每一行是通道中的时间、值数据点。每一行的格式为:
时间(毫秒),值,置信度
其中,时间(毫秒)是以毫秒为单位的数据点的时间,值是该数据点的通道值。置信度一般不使用,设置为 0.0。例如:
1857.000,1.424,0.000
表示时间为 1857 毫秒的数据点,值为 1.424。
插值函数
就目前而言,所有 SGX ITS 文件都使用恒定插值。这意味着在两个时间点之间的通道值是恒定的。具体来说,任何时间的通道值都是下一个即将到来的数据点的值。例如

对于恒定插值,数据点 A 的值设置为以 A 为终点的时间区间的值,而数据点 B 的值设置为以 B 为终点的时间区间的值。
分类时间序列
分类时间序列包含一组带有标注的区间和可能的子区间。例如,下面是一个音素对齐的示例,它是一个具有两层的 CTS:单词和音素。

文件格式 (.seg)
分类时间序列的文件格式(注意其后缀为 .seg,表示“分段”,而不是 .cts)包含一个区间边界列表:
1370.0 0.000 [^] [^]
1550.0 0.000 [t]
1680.0 0.000 [aa]
1820.0 0.000 [ih]
1920.0 0.000 [g]
1980.0 0.000 [ax] [tyger]
2160.0 0.000 [t]
2290.0 0.000 [aa]
2390.0 0.000 [ih]
2520.0 0.000 [g]
2660.0 0.000 [ax] [tyger]
2840.0 0.000 [^] [^]
2920.0 0.000 [b]
3100.0 0.000 [ehx]
3160.0 0.000 [n]
3210.0 0.000 [ih]
3340.0 0.000 [ng] [burning]
3430.0 0.000 [b]
3480.0 0.000 [rh]
3610.0 0.000 [aa]
3740.0 0.000 [ih]
4030.0 0.000 [t] [bright]
4520.0 0.000 [^] [^]
4630.0 0.000 [ih]
4720.0 0.000 [n] [in]
4760.0 0.000 [dh]
4820.0 0.000 [ax] [the]
4980.0 0.000 [f]
5080.0 0.000 [oa]
5180.0 0.000 [rh]
5250.0 0.000 [ih]
5360.0 0.000 [s]
5470.0 0.000 [t]
5610.0 0.000 [s] [forests]
5740.0 0.000 [oa]
5850.0 0.000 [v] [of]
5900.0 0.000 [dh]
5960.0 0.000 [ax] [the]
6060.0 0.000 [n]
6180.0 0.000 [aa]
6310.0 0.000 [ih]
6590.0 0.000 [t] [night]
7460.0 0.000 [^] [^]
每个边界定义包含:
-
一个时间值(以毫秒为单位)
-
一个置信度值(通常设置为 0.0)
-
一个标签序列(以方括号表示)
边界上标签的数量决定了边界跨越的层数。例如,边界
2660.0 0.000 [ax] [tyger]
有两个标签,这意味着它跨越了两层。下面的红线表示这条边界:

在边界跨越的每一层上,都会标记一个片段的终点,并给该片段贴上相应的标签。每个片段的起点是同一层上的前一个边界(如果没有边界,则为 0.0)。因此,在第一层(音素层),红色边界标记出了 [ax] 片段的终点,该片段的起点是第一层的前一个边界:

而在第二层(单词层),红色边界标记出了 [tyger] 分段的终点,该分段的起点是第二层的前一个边界:
