
SGX 的核心功能是将音频(以及可选的文本)转换为同步动画。这一功能通过音频分析、神经网络和肌肉动态模拟相结合而实现(请参阅 Speech Graphics Technology 技术)。
处理音频文件时,首先要将音频文件及其相应的文本导入到 event 中。
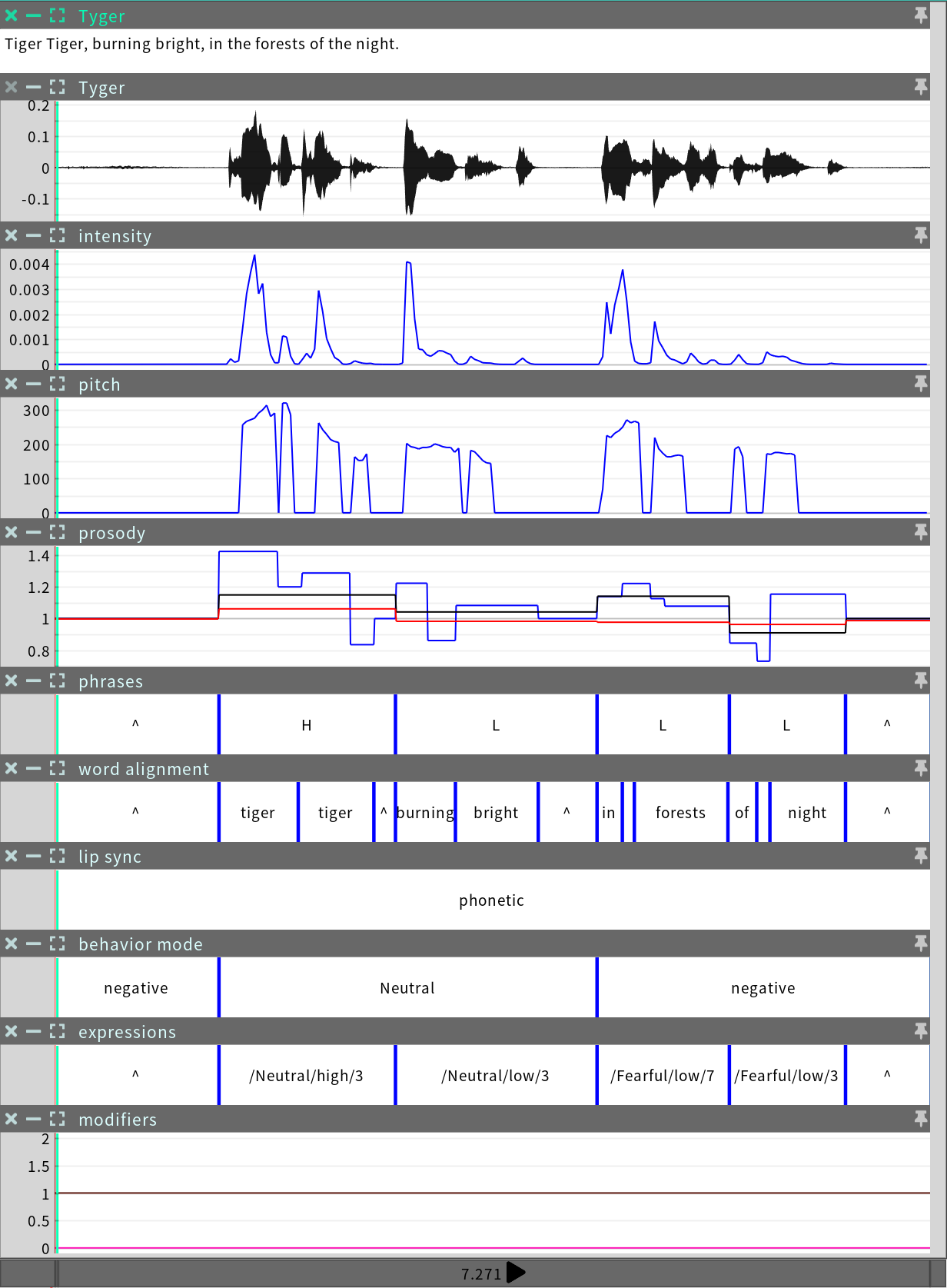
然后,SGX 算法会分析输入的音频和文本,并生成相应的动作。在这一分析过程中,音频时间轴上还会产生多个元数据表示。所有这些序列都会附加到 event 中,随后该 event 文件会被保存。
Event 处理可以通过 SGX Director 的 GUI 界面以交互方式执行,也可以在 SGX Producer 中以批量处理方式执行。
基于语音的和基于原声的嘴型同步处理
SGX 处理结合了两种不同的嘴型同步系统,我们分别称之为基于语音的和基于原声的嘴型同步系统。基于语音的嘴型同步系统利用文本作为音频的补充,而基于原声的嘴型同步系统不需要。由于文本提供了额外的信息,基于语音的系统通常可以实现比基于原声的系统更高质量的嘴型同步。
有三种情况会自动触发基于原声的系统:
-
未使用文本时
-
未使用语言模块时
-
基于语音的分析置信度较低时
在第三种情况下,基于原声的分析会取代基于语音的分析,以解决基于语音的分析中存在的问题。这有助于提高基于语音的分析的可靠性。由于这些自动校正的存在,event 过程中所使用的嘴型同步系统可能会发生变化。这些变化应该是无缝的。但是,嘴型同步系统的选择在元数据中可见,并且可以在 SGX Director 的时间轴上进行编辑(请参阅编辑 Events)。
Events 中有一个度量值称为基于语音的分析得分,指的是在event 中,基于语音的系统被确认为是正确的,并得到使用的比例。