
The central function of SGX is to convert audio (and optional transcripts) into synchronous animation. This happens through a combination of audio analyses, neural networks and muscle dynamic simulations (see Speech Graphics Technology).
When an audio file is processed, the first thing that happens is that it is imported, along with its corresponding transcript, into an event.
Then, SGX algorithms analyze the input audio and transcript, and generate corresponding motion. In the course of this analysis, a number of metadata representations are also produced on the audio timeline. All of these sequences are appended to the event. Then the event file is saved.
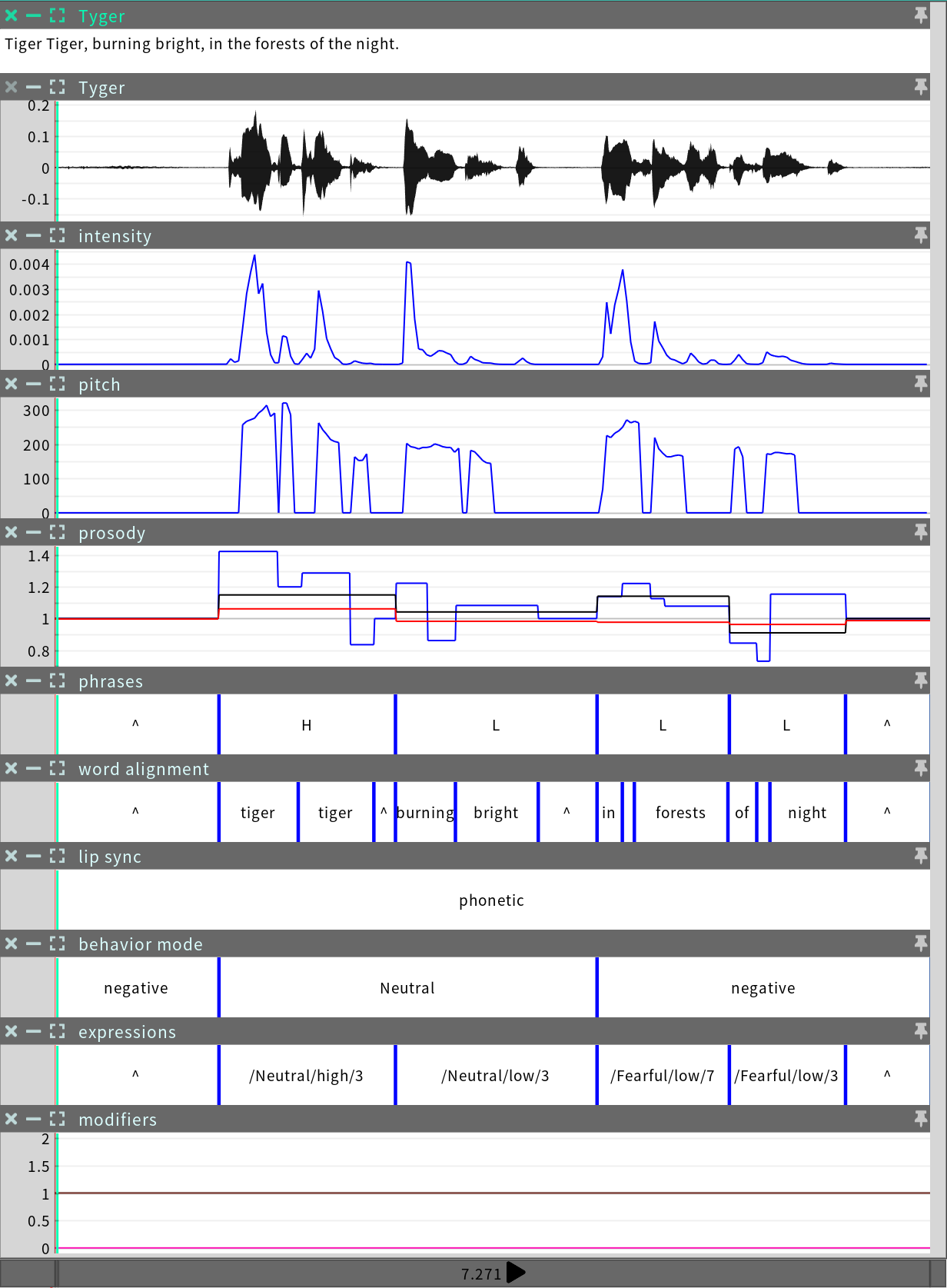
Event processing may be performed either interactively in the GUI in SGX Director, or as a batch process in SGX Producer.
Phonetic and Acoustic lip sync processing
SGX processing combines two different lip sync systems, which we call phonetic and acoustic. The phonetic lip sync system utilizes the transcript as a supplement to the audio, whereas the acoustic lip sync system does not. The phonetic system can usually achieve higher quality lip sync than the acoustic system because of the additional information provided by the transcript.
There are three conditions under which the acoustic system is automatically triggered:
-
When a transcript is not used
-
When a language module is not used
-
When there is low confidence in the phonetic analysis
Under the third condition the acoustic analysis takes over to fix problems in the phonetic analysis. This helps make the phonetic analysis very robust. Because of these auto-corrections, the lip sync system being used may change over the course of an event. These changes should be seamless. However, the choice of lip sync system is visible in the metadata and can be edited on the timeline in SGX Director (see Editing Events).
Events have a measure called phonetic analysis score, which refers to the proportion of the event during which the phonetic system was deemed correct and was therefore used.