
SGX 旨在为大量音频高效制作高质量的脸部动画。为此,我们提供了批量处理功能。批量处理由 SGX Producer 执行,这是一个适用于 Windows 的命令行可执行文件。SGX Director 中还有一个用户友好的批量处理界面,可启动 SGX Producer 批量处理和/或打印可启动这些批量处理的命令。
批量处理有两种模式:
-
处理新 events
-
处理现有 events
处理新 events
在这种模式下,需要将新音频和文本指定为输入。要为批量处理准备输入,请参阅批量输入格式。对于每个输入音频文件,都将创建一个新的 event 文件,其基本名称与音频文件相同。下面的示例显示了一组输入文件(左)和相应的已完全处理的 event 文件(右)。
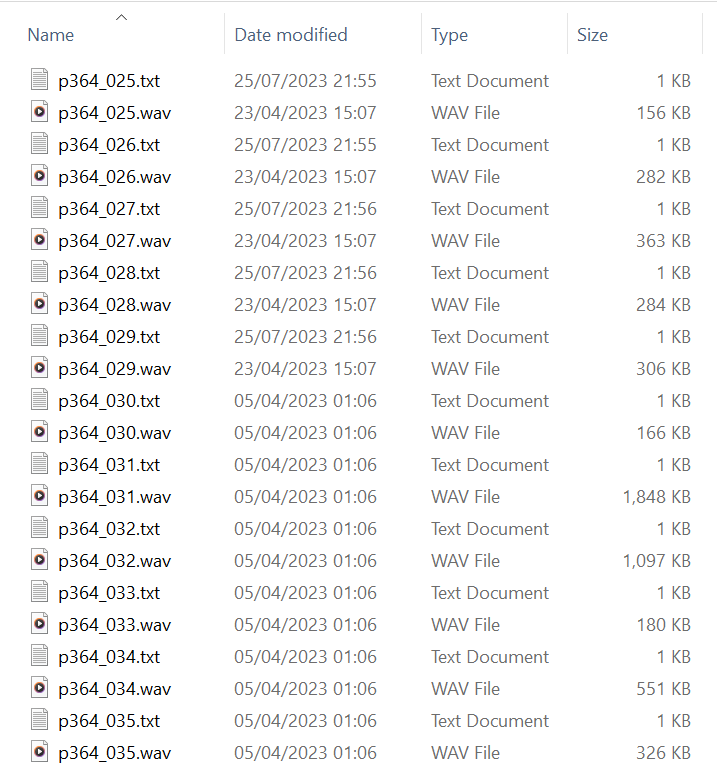
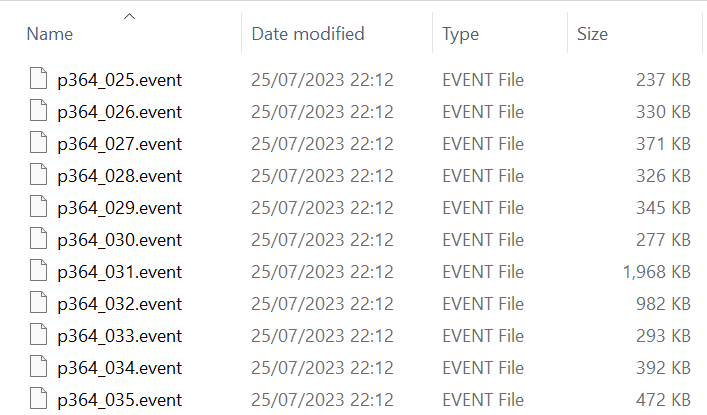
处理现有 events
在处理批量现有 events 时,需要将包含这些 events 的目录指定为输入。Events 文件将就地处理,这意味着不会创建新文件;现有文件将被覆盖。要处理批量现有 events 的原因有两个:
批量报告
除了生成或更新 event 文件外,批量处理还会生成两个文件,对批量处理的情况进行总结。这两个文件与已处理的 event 文件位于同一目录下:
|
|
包含批量命令参数记录的文本文件 |
|
|
包含处理报告的 CSV 文件 |
其中 TIMESTAMP 的格式为
yyyymmddThhmmss
示例:
20230929T164937
处理报告为每个 event 一行,包含以下逗号分隔的值:
name,path,processing_status,transcript_status,phonetic_analysis_score,pre_roll,post_roll
下表提供了每个 event 的报告属性说明:
|
属性 |
值 |
描述 |
|
name |
|
Event 的基本名称 |
|
path |
|
Event 的文件路径 |
|
processing_status |
{0,1} |
处理是否成功(0=失败,1=成功) |
|
transcript_status |
{0,1} |
是否找到并使用了语音文本(0=否,1=是) |
|
phonetic_analysis_score |
[0,1] |
基于语音的嘴型同步的准确度,决定了使用程度(请参阅基于语音的和基于原声的嘴型同步处理)。 |
|
pre_roll |
[0,…] |
预缓冲帧的时长(以毫秒为单位) |
|
post_roll |
[0,…] |
后缓冲帧的时长(以毫秒为单位) |
下面是一个批量报告 .csv 文件示例,以电子表格形式显示:
|
name |
路径 |
处理状态 |
文本状态 |
基于语音的分析得分 |
预缓冲帧 |
后缓冲帧 |
|
|
|
1
|
1
|
0.84 |
18.21 |
42.79 |
|
|
|
1 |
1
|
0.79 |
0 |
216.68 |
|
|
|
1 |
0 |
0 |
15.9 |
16.41 |
|
|
|
1 |
1 |
0.99 |
103.43 |
136.37 |
|
|
|
1 |
1 |
0.95 |
0 |
401.91 |
|
|
|
0
|
0 |
0 |
0 |
0 |
|
|
|
1
|
1 |
0.91 |
13.43 |
136.37 |
|
|
|
1 |
1 |
0.89 |
0 |
136.37 |
|
|
|
1 |
1 |
0.65 |
103.43 |
0 |
|
|
|
1 |
1 |
0.77 |
29.02 |
432.31 |
|
|
|
1 |
1 |
0.99 |
0 |
0 |