
このセクションでは、SGX Directorのイベントエディターに表示されるSGX独自の時系列データタイプと、それらを保存したときのファイル形式について説明します。SGXの時系列には、以下の3つのタイプがあります。
-
規則時系列
-
不規則時系列
-
分類別時系列
上記時系列について、以下で詳しく説明します。
規則時系列
規則時系列(RTS)には、マルチチャンネルのデータが規則的なサンプリングレートで記録されています。以下の例は、アニメーションのデータが記録されているRTSです。各行はアニメーションのチャンネルを表しており、サンプリングレートはアニメーションのフレームレートです。
ファイル形式(.rts)
このファイルには、以下の3つのパートがあります。
-
1行目はサンプリングレートです。
-
2行目はチャンネルのラベルをカンマ区切りで並べたものです。
-
以降の行は、1行目のサンプリングレートでのチャンネルの値のサンプルです。
30
head.tx,head.ty,head.tz,head.rx,head.ry,head.rz,head.sx,head.sy,...
1.999987416,3.86E-06,-1.80E-06,-0.000571836,-0.002572273,-0.0001...
1.999848472,9.27E-05,-1.87E-05,-0.005927532,-0.026663633,-0.0065...
1.999549227,0.000318193,-5.29E-05,-0.016749984,-0.075345895,-0.0...
1.999104374,0.000668944,-0.000102617,-0.032516878,-0.146269352,-...
1.998546331,0.001117568,-0.00016447,-0.052116501,-0.234432717,-0...
1.997909577,0.001634493,-0.000234717,-0.074376584,-0.334562011,-...
1.997233413,0.002185685,-0.000309162,-0.097967676,-0.440676092,-...
...
不規則時系列
不規則時系列(ITS)には、補間関数を使用して不規則にサンプリングされたマルチチャンネルデータが記録されています。ITSの例としては、音節の強弱、フレーズの強弱、フレーズの速度という3つのチャンネルを持つ韻律があります。
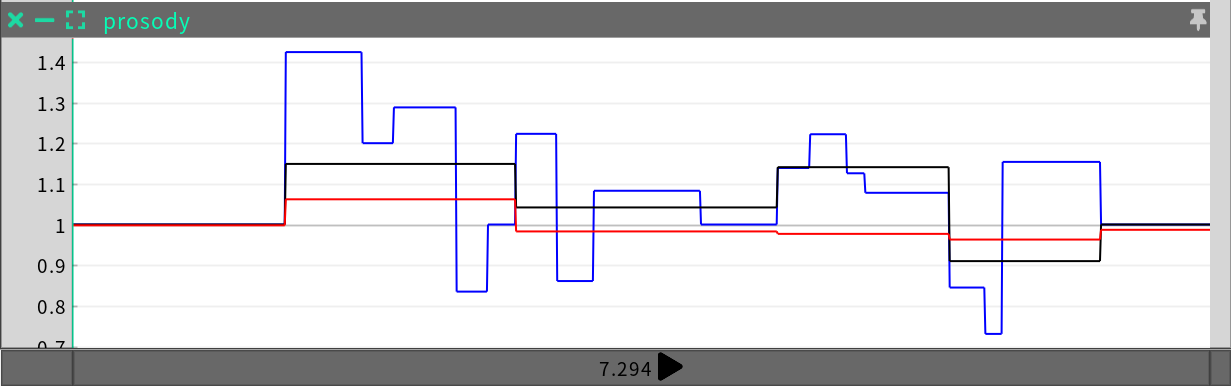
ファイル形式(.its)
このファイルには、各チャンネルについて、見出しと不規則なタイミングで取得されたサンプルが記録されています。
"syllable_stress" >constant
1370.000,1.000,0.000
1857.000,1.424,0.000
2057.000,1.200,0.000
2462.000,1.288,0.000
2660.000,0.835,0.000
2840.000,1.000,0.000
3107.000,1.223,0.000
3340.000,0.861,0.000
4030.000,1.083,0.000
4520.000,1.000,0.000
4730.000,1.139,0.000
4967.000,1.222,0.000
5080.000,1.126,0.000
5622.000,1.078,0.000
5850.000,0.845,0.000
5962.000,0.731,0.000
6590.000,1.154,0.000
7294.125,1.000,0.000
"phrase_stress" >constant
1370.000,1.000,0.000
2840.000,1.149,0.000
4520.000,1.042,0.000
5622.000,1.141,0.000
6590.000,0.910,0.000
7294.125,1.000,0.000
"phrase_speed" >constant
1370.000,0.998,0.000
2840.000,1.062,0.000
4520.000,0.983,0.000
5622.000,0.977,0.000
6590.000,0.963,0.000
7294.125,0.987,0.000
各チャンネルセクションの1行目はチャンネルのヘッダーで、以下の構造になっています。
"<チャンネル名>" ><補間関数>
たとえば、以下のようになります。
"syllable_stress" >constant
ヘッダーに続く行は、<タイム>,<値>形式のチャンネルのデータポイントです。各行は、以下の形式になっています。
<タイム(ミリ秒)>,<値>,<信頼度>
<タイム(ミリ秒)>はデータポイントのタイム(ミリ秒単位)で、<値>は、そのデータポイントでのチャンネルの値です。通常、<信頼度>は使用されず、0.0に設定されています。たとえば、以下のようになります。
1857.000,1.424,0.000
これは、1,857msが経過した時点でのデータポイントの値が1.424であることを表しています。
補間関数
現在の目的上、SGXのITSファイルはすべて定数補間を採用しているため、ある時点から次の時点までのチャンネルの値は一定になります。つまり、ある時点のチャンネルの値は、次のデータポイントの値ということです。以下に例を示します。

定数補間では、データポイントAで終了する区間の値はデータポイントAの値で、データポイントBで終了する区間の値はデータポイントBの値です。
分類別時系列
分類別時系列(CTS)は、ラベルが付いた区間と(ある場合は)下位区間がセットになったものです。CTSの例としては言語音の位置合わせがありますが、こちらは単語と言語音の2層構造になっています。

ファイル形式(.seg)
分類別時系列のファイル形式には(注:拡張子は.ctsではなく、「segmentation」(セグメント化)を意味する.segです)、各区間の境界の一覧が記録されています。
1370.0 0.000 [^] [^]
1550.0 0.000 [t]
1680.0 0.000 [aa]
1820.0 0.000 [ih]
1920.0 0.000 [g]
1980.0 0.000 [ax] [tyger]
2160.0 0.000 [t]
2290.0 0.000 [aa]
2390.0 0.000 [ih]
2520.0 0.000 [g]
2660.0 0.000 [ax] [tyger]
2840.0 0.000 [^] [^]
2920.0 0.000 [b]
3100.0 0.000 [ehx]
3160.0 0.000 [n]
3210.0 0.000 [ih]
3340.0 0.000 [ng] [burning]
3430.0 0.000 [b]
3480.0 0.000 [rh]
3610.0 0.000 [aa]
3740.0 0.000 [ih]
4030.0 0.000 [t] [bright]
4520.0 0.000 [^] [^]
4630.0 0.000 [ih]
4720.0 0.000 [n] [in]
4760.0 0.000 [dh]
4820.0 0.000 [ax] [the]
4980.0 0.000 [f]
5080.0 0.000 [oa]
5180.0 0.000 [rh]
5250.0 0.000 [ih]
5360.0 0.000 [s]
5470.0 0.000 [t]
5610.0 0.000 [s] [forests]
5740.0 0.000 [oa]
5850.0 0.000 [v] [of]
5900.0 0.000 [dh]
5960.0 0.000 [ax] [the]
6060.0 0.000 [n]
6180.0 0.000 [aa]
6310.0 0.000 [ih]
6590.0 0.000 [t] [night]
7460.0 0.000 [^] [^]
各境界の定義は以下のとおりです。
-
タイム値(ミリ秒単位)
-
信頼度値(通常は0.0)
-
各ラベルを角かっこ([ ])で囲んだもの
各境界のラベルの数によって、その境界がまたがる階層の数が決まります。たとえば、以下の境界を見てみましょう。
2660.0 0.000 [ax] [tyger]
この場合、ラベルは2つなので、2つの階層にまたがっていることになります。この境界の位置は、下に赤色の線で示した箇所です。

この境界は、またがっている各階層でセグメントの終点となっており、そのセグメントに対応するラベルを付与しています。各セグメントの始点は、同じ階層にある1つ前の境界です(ない場合は0.0)。したがって、1つ目の階層(言語音)では、赤い境界は、[ax]というセグメントの終点となっており、始点は同じ階層の1つ前の境界となっています。

また、2つ目の階層(単語)では、赤い境界は[tyger]というセグメントの終点となっており、始点は同じ階層の1つ前の境界となっています。

[^]は、空のセグメントであることを意味します。この記号の意味はメタデータによって異なります。